Lineær regression
Introduktion
Lineær regression, dvs. linjens ligning for et sæt tal med en lineær afhængighed, består af to elementer: selve funktionen der bestemmer hældning og skæring med y-aksen, og en funktion der bestemmer R²-værdien, dvs. hvor godt talsættet passer med en ret linje. Som det ses i sidste afsnit, kan man vælge at lave regressionen i en udviddet udgave, som har R²-værdien med som en del af de returnerede værdier.
Hældning og skæring med y-aksen
Funktionen for lineær regression, hvor man bestemmer hældningen og skæringen med y-aksen, eller y-interceptet som nogle kalder det, hedder LINEST(). Har man en dansk version af Excel, hedder funktionen LINREGR(). Ved brug af LINEST() skal man være opmærksom på, at den anvender to celler ved siden af hinanden, dvs. man skriver funktionen i den ene celler og så bliver nabocellen til højre automatisk inddraget.
Ved anvendelse af LINEST(), skal der i parantensen først angives f(x)-værdierne, og derefter de tilhørende x-værdier. De to talsæt adskilles med semikolon, dvs. LINEST(f(x)-værdierne; x-værdierne). Værdierne der returneres er hhv. a og b for linjens ligning y = ax + b. Til LINEST() er der også to valgfrie parametre, som tilføjes efter x-værdierne. Disse bliver gennemgået længere nede på siden. I eksemplet med Excel nedenunder, kan man se koden som den er skrevet i celle E5. I celle F6 skriver Excel den samme kode, men den står her med grå skrift. Calc gør det lidt anderledes. Når man skriver koden og trykket enter, sætter Calc koden i krøllede paranteser og laver en kopi af dette i celle F6. Fordi Calc indsætter koden i to celler som et array, tillader Calc ikke at man redigerer eller sletter koden ved kun at redigere i den ene celle, som man normalt kan. Her skal man markere begge celler samtidig, før man kan komme til at redigere eller slette koden.
For Microsoft Excel ser det således ud:

For OpenOffice Calc ser det således ud:
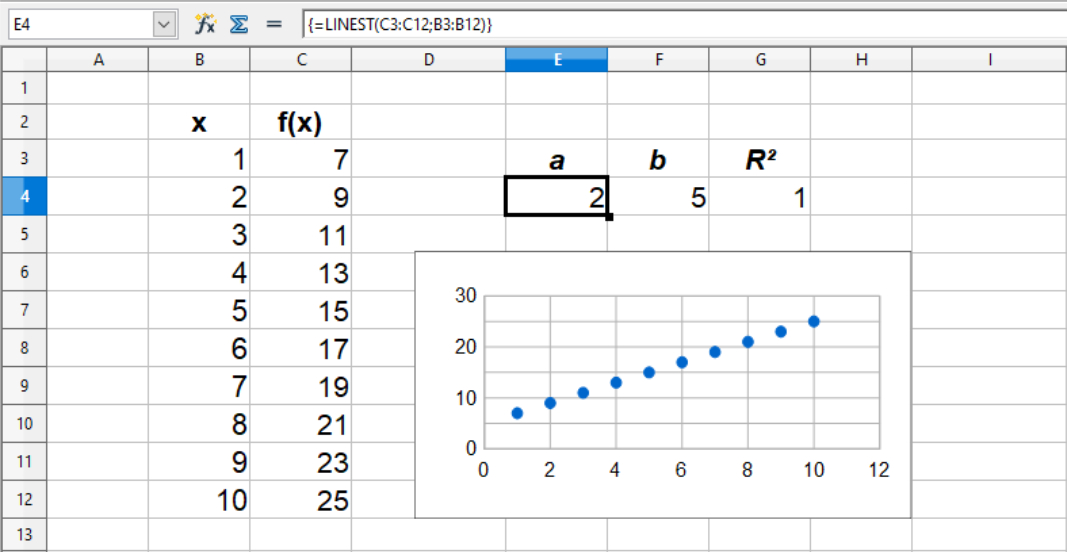
Ved anvendelse af LINEST(), skal der i parantensen først angives f(x)-værdierne, og derefter de tilhørende x-værdier. De to talsæt adskilles med semikolon, dvs. LINEST(f(x)-værdierne; x-værdierne). Værdierne der returneres er hhv. a og b for linjens ligning y = ax + b. Til LINEST() er der også to valgfrie parametre, som tilføjes efter x-værdierne. Disse bliver gennemgået længere nede på siden. I eksemplet med Excel nedenunder, kan man se koden som den er skrevet i celle E5. I celle F6 skriver Excel den samme kode, men den står her med grå skrift. Calc gør det lidt anderledes. Når man skriver koden og trykket enter, sætter Calc koden i krøllede paranteser og laver en kopi af dette i celle F6. Fordi Calc indsætter koden i to celler som et array, tillader Calc ikke at man redigerer eller sletter koden ved kun at redigere i den ene celle, som man normalt kan. Her skal man markere begge celler samtidig, før man kan komme til at redigere eller slette koden.
For Microsoft Excel ser det således ud:
For OpenOffice Calc ser det således ud:
R²-værdien
R²-værdien er et mål for hvor godt punkterne ligger på linje. For et datasæt hvor alt ligger helt på linje, vil R²-værdien være 1. Afvigelser, som demonstreres længere nede, giver en lavere værdi.
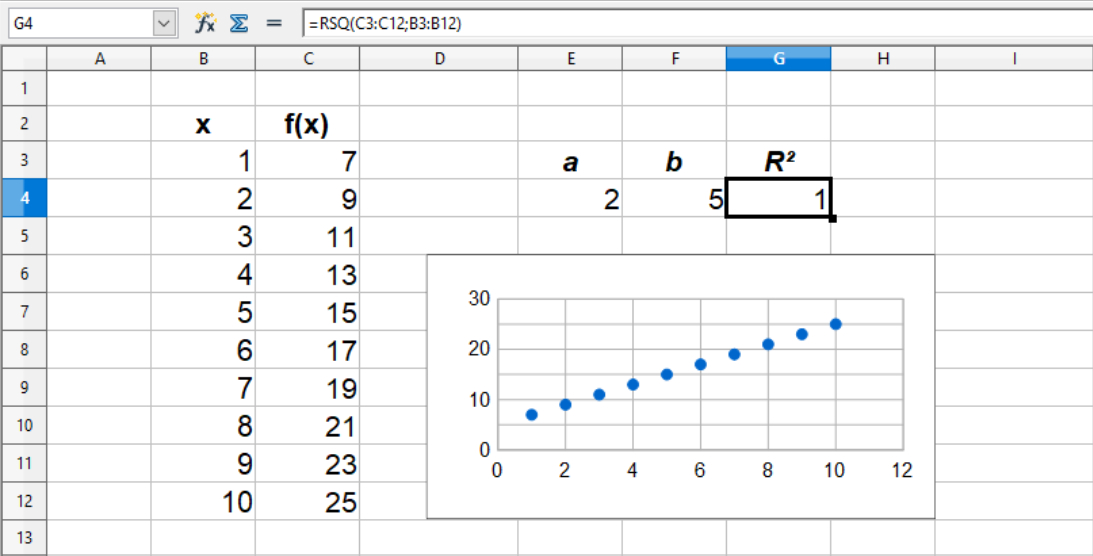
Funktionen for R²-værdien er RSQ(). Har man en dansk version af Excel hedder funktionen FORKLARINGSGRAD(). Ved anvendelse af RSQ(), skal der i parantensen først angives f(x)-værdierne, og derefter de tilhørende x-værdier. De to talsæt adskilles med semikolon, dvs. RSQ(f(x)-værdierne; x-værdierne).
For Microsoft Excel ser det således ud:

For OpenOffice Calc ser det således ud:
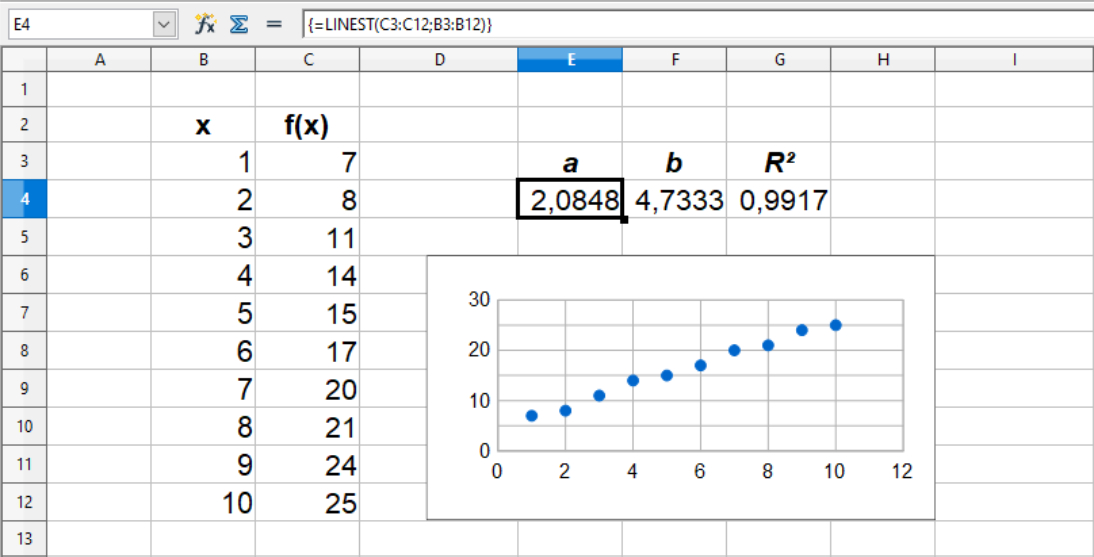
Hvis vi kigger på et datasæt, hvor talværdierne ikke ligger perfekt på en linje, som man vil se ved f.eks. analyser, ser vi at R²-værdien bliver mindre end 1 og a og b afviger også fra de oprindelige værdier.
For Microsoft Excel ser det således ud:

For OpenOffice Calc ser det således ud:
Man skal være opmærksom på, at R²-værdien ikke er et mål for hvor god eller korrekt regressionsberegningen er, ligeledes er R²-værdien ikke et mål for hvor gode resultaterne er. Begge disse ting ligger i den måde hvorpå målingerne/ observationerne er lavet. R²-værdien siger kun noget om den samlede spredning, dvs. hvor tæt talsættene samlet set er på at ligge på en ret linje.
Funktionen for R²-værdien er RSQ(). Har man en dansk version af Excel hedder funktionen FORKLARINGSGRAD(). Ved anvendelse af RSQ(), skal der i parantensen først angives f(x)-værdierne, og derefter de tilhørende x-værdier. De to talsæt adskilles med semikolon, dvs. RSQ(f(x)-værdierne; x-værdierne).
For Microsoft Excel ser det således ud:
For OpenOffice Calc ser det således ud:
Hvis vi kigger på et datasæt, hvor talværdierne ikke ligger perfekt på en linje, som man vil se ved f.eks. analyser, ser vi at R²-værdien bliver mindre end 1 og a og b afviger også fra de oprindelige værdier.
For Microsoft Excel ser det således ud:
For OpenOffice Calc ser det således ud:
Man skal være opmærksom på, at R²-værdien ikke er et mål for hvor god eller korrekt regressionsberegningen er, ligeledes er R²-værdien ikke et mål for hvor gode resultaterne er. Begge disse ting ligger i den måde hvorpå målingerne/ observationerne er lavet. R²-værdien siger kun noget om den samlede spredning, dvs. hvor tæt talsættene samlet set er på at ligge på en ret linje.
Den udvidede LINEST()-funktion
LINEST() har to valgfrie parametre. I Excel hedder de const og stats (hhv. konstant og statistik hvis man har en dansk version af Excel). I Calc hedder de Linear_type og stats. Med disse man kan lave lidt mere end bare at finde a og b for linjens ligning.
const/Linear_type gør at man kan tvinge b-værdien til at være 0, dvs. linjen skal gå gennem (0,0). Her er der en forskel på Excel og Calc. Ved Excel bruger man TRUE hvis b skal bestemmes normalt (default) og FALSE, hvis linjen skal tvinges gennem (0,0). Har man en dansk version af Excel, bruger man SAND og FALSK. Ved Calc bruger man 0, hvis linjen skal tvinges gennem (0,0), og ved alle andre værdier (inklusiv ingen værdi) bestemmes b normalt (default). Calc synes her at acceptere alle tal, også negative tal og kommatal.
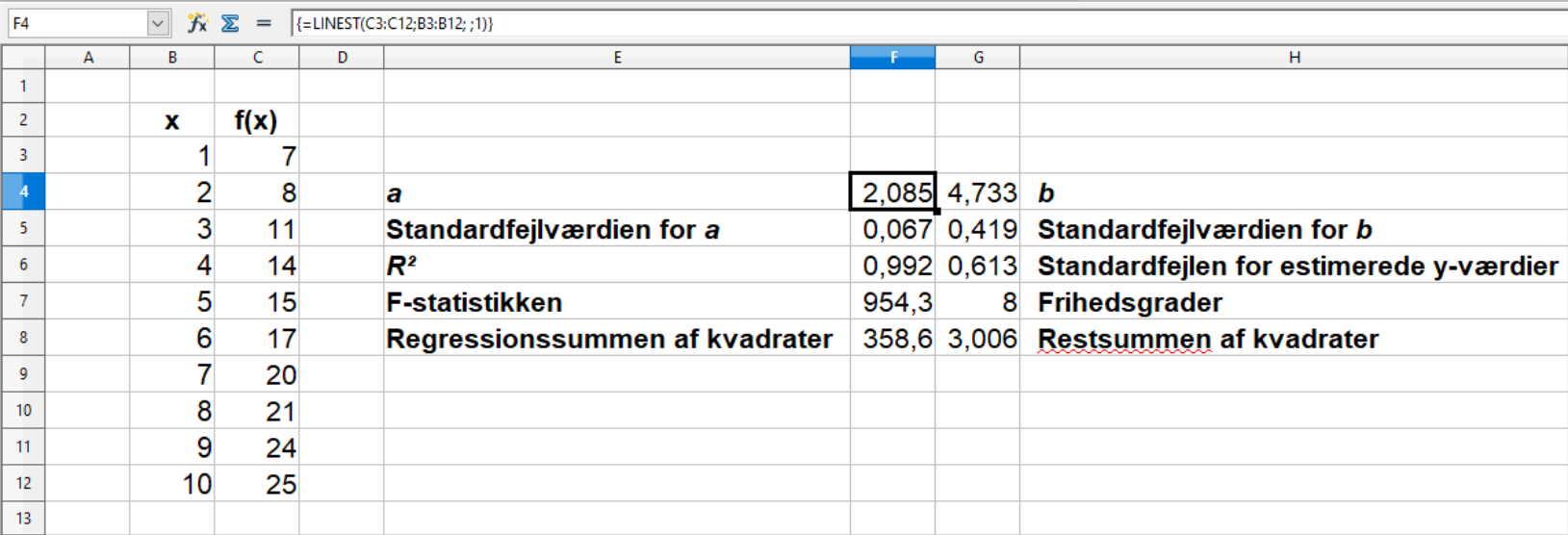
Med stats kan man lave yderligere regressionsstatistik, og her bliver det lidt kompliceret. For Excel kan man vælge TRUE, hvis man vil have den udvidede regressionsstatistik, og FALSE, hvis man ikke vil have den. FALSE er default. Har man en dansk version af Excel, bruger man SAND og FALSK. Ved Calc bruger man 0, man ikke vil have den udvidede regressionsstatistik (default), og ved alle andre værdier (inklusiv ingen værdi) får man den udvidede regressionsstatistik. Calc synes her at acceptere alle tal, også negative tal og kommatal. For overskuelighedens skyld bruger vi 1 her.
Når man vælger stats med de to regneark, får man blot fem rækker tal i to søjler, uden nogen form for angivelse af hvad de er, hvilket kan virke både forvirrende og uhensigtsmæssig. I de nedenstående eksempler er det anført ud for tallene, hvilke værdier der er tale om, så tallene giver mere mening.
For Microsoft Excel ser det således ud:

For OpenOffice Calc ser det således ud:
const/Linear_type gør at man kan tvinge b-værdien til at være 0, dvs. linjen skal gå gennem (0,0). Her er der en forskel på Excel og Calc. Ved Excel bruger man TRUE hvis b skal bestemmes normalt (default) og FALSE, hvis linjen skal tvinges gennem (0,0). Har man en dansk version af Excel, bruger man SAND og FALSK. Ved Calc bruger man 0, hvis linjen skal tvinges gennem (0,0), og ved alle andre værdier (inklusiv ingen værdi) bestemmes b normalt (default). Calc synes her at acceptere alle tal, også negative tal og kommatal.
Med stats kan man lave yderligere regressionsstatistik, og her bliver det lidt kompliceret. For Excel kan man vælge TRUE, hvis man vil have den udvidede regressionsstatistik, og FALSE, hvis man ikke vil have den. FALSE er default. Har man en dansk version af Excel, bruger man SAND og FALSK. Ved Calc bruger man 0, man ikke vil have den udvidede regressionsstatistik (default), og ved alle andre værdier (inklusiv ingen værdi) får man den udvidede regressionsstatistik. Calc synes her at acceptere alle tal, også negative tal og kommatal. For overskuelighedens skyld bruger vi 1 her.
Når man vælger stats med de to regneark, får man blot fem rækker tal i to søjler, uden nogen form for angivelse af hvad de er, hvilket kan virke både forvirrende og uhensigtsmæssig. I de nedenstående eksempler er det anført ud for tallene, hvilke værdier der er tale om, så tallene giver mere mening.
For Microsoft Excel ser det således ud:
For OpenOffice Calc ser det således ud: